使用GitHub项目boml学习双层优化
时间:2024年2月29日-2024年3月6日,2024年3月13日-14日, 2024年3月30日-4月1日
额外安装相关内容见Colab配置版
最新进展看BDA项目学习
# 初始化需要使用的代码# wget https://file.cz123.top/3PhD/4BDA/Codes/ToBOML.sh && bash ToBOML.sh# 下面是colab-gpu版本(默认使用)wget https://file.cz123.top/3PhD/4BDA/Codes/ToBOML_Colab.sh && bash ToBOML_Colab.sh# 运行完后执行以下代码后初始化完成source ~/.bashrc # 正确配置软链接source ~/tf-env-BDA/bin/activate # 进入可以正常运行的python环境
目录
使用GitHub项目boml学习双层优化目录前言资源vis-opt-group/BDA1 构建可以运行的环境2 具体分析代码先看可以执行的Data_hyper_cleaning.py 文件dut-media-lab/BOML1 构建可以运行的环境2 具体实例代码使用3 Bug/Warning分析4 核心模组5 核心内置函数6 例子分析7 要理解代码首先需要解决的问题8 以上述问题为导向理解boml项目使用boml模拟常见的所有类型的双层优化问题可能的选择组合(2024年3月6日)具体Debug和分析(3月13日)发现有其他三个可以运行的版本例子脚本的使用与修改其他
前言
基于对于深度学习的python包的不熟悉程度,以及对于双层优化的不熟悉程度,在长时间自己写代码以保证能有较好运行结果失败的情况下,转而尝试使用TF更低一点的版本,至少保证在别人能运行的基础上可以证实这条路的可用性。
资源
最初遇到的版本:vis-opt-group/BDA
上面的项目中的 boml项目: dut-media-lab/BOML或者看主页 https://boml.readthedocs.io/en/latest/
新发现的 boml项目:pauchingyap/BOML(由于此处的BOML是指贝叶斯在线元学习和前面的双层优化元学习不一样,故弃之。)文献地址
计算资源更新(2024年3月13日):本来一直是使用vultr配置满足BDA的服务器环境(由于成本不高同时可以随时取消重构),以完成搭建环境的一键脚本。目前脚本已经完成,转向可以有更高的计算资源的Colab,并且已经完成在Colab上的使用验证。
{kind=link}
vis-opt-group/BDA
1 构建可以运行的环境
通过执行shell脚本:https://github.com/Cz1544252489/DailyWork/releases/download/BDA/ToBDA.sh
xxxxxxxxxxwget https://github.com/Cz1544252489/DailyWork/releases/download/BDA/ToBDA.sh && bash ToBDA.sh
2 具体分析代码
先看可以执行的Data_hyper_cleaning.py 文件
可以看此链接:https://github.com/vis-opt-group/BDA/blob/main/test_script/Data_hyper_cleaning.py
导入的主要包有:tensorflow.contrib.layers, sys, os, sklearn, numpy, tensorflow
还使用标准库中的包 argparse制作一个用户友好的命令行界面。
接着定义了如下函数:save_obj, cross_entropy_loss, outer_cross_entropy_loss, F1_score, pollute, get_data, get_fashion_mnist_data, g_logits
dut-media-lab/BOML
1 构建可以运行的环境
通过执行shell脚本:https://github.com/Cz1544252489/DailyWork/blob/main/shell%20script/ToBOML.sh
2 具体实例代码使用
下载文件后,安装,参考:https://boml.readthedocs.io/en/latest/
在BOML文件夹下,有example.py文件,可以运行成功。
安装记录:
2024年3月2日 13:15 出现需要降级protobuf包以解决问题的bug,重新安装。
2024年3月2日 14:40 由下面的安装流程后成功运行,实例文件 example.py
安装流程:
初始化完成后运行下面代码:
xxxxxxxxxxwget https://file.cz123.top/3PhD/4BDA/Codes/ToBOML.sh && bash ToBOML.sh# 下面是colab-gpu版本wget https://file.cz123.top/3PhD/4BDA/Codes/ToBOML_Colab.sh && bash ToBOML_Colab.sh此时如果直接运行会出现先前面的bug,运行下面代码以降低protobuf:
xxxxxxxxxx# 先进入独立环境cd && source tf-env-BDA/bin/activate# pip install protobuf==3.20.* (已经加入到步骤1中了)虽然确实会出现一堆乱七八糟的bug,但是确实后面可以运行了。
3 Bug/Warning分析
xxxxxxxxxx/root/tf-env-BDA/lib/python3.7/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'._np_qint8 = np.dtype([("qint8", np.int8, 1)])
此类型提示由Numpy给出,表示代码中使用的语法太旧,可以调整但影响不大。
xxxxxxxxxxEnvironment variable DATASETS_FOLDER not found. Variables HELP_WIN and HELP_UBUNTU contain info.Data folder is /root/BOML/data
暂未设置环境变量DATASETS_FOLDER,使用了默认位置。
xxxxxxxxxxWARNING:tensorflow:From /root/BOML/boml/extension.py:37: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.
此类型提示由tensorflow给出,表示代码中使用的语法太旧,可以调整但影响不大。
另外,可以使用以下方法避免显示Warning(来自ChatGPT,有交叉验证,但暂时仍然无效):
忽略所有警告:
xxxxxxxxxximport warningswarnings.filterwarnings("ignore")忽略部分警告:
xxxxxxxxxximport warningswarnings.filterwarnings("ignore", category=FutureWarning)使用命令行:
xxxxxxxxxxpython -W ignore my_script.py4 核心模组
见:https://boml.readthedocs.io/en/latest/modules.html
load_data: boml.load_data manages different datasets and generate batches of tasks for training and testing.
x# 例子boml.meta_omniglot( folder=DATA_FOLDER, # folder: str, root folder name. std_num_classes=None, # std_num_classes: number of classes for N-way classification examples_train=None, # examples_train: number of examples to be picked in each generated per classes for training (eg .1 shot, examples_train=1) examples_test=None, # examples_test: number of examples to be picked in each generated per classes for testing one_hot_enc=True, # one_hot_enc: whether to adopt one hot encoding _rand=0, # _rand: random seed or RandomState for generate training, validation, testing meta-datasets split n_splits=None) # n_splits: num classes per split
# 使用方法dataset = boml.meta_omniglot(args.num_classes,args.num_examples,args.examples_test)Experiment: boml.Experiment manages inputs, outputs and task-specific parameters.
xxxxxxxxxxboml.Experiment( dataset=None, # dataset: initialized instance of load_data dtype=tf.float32 # dtype: default tf.float32 )
# 属性# x: input placeholder of input for your defined lower level problem# y: label placeholder of output for yourdefined lower level problem# x_:input placeholder of input for your defined upper level problem# y_:label placeholder of output for your defined upper level problem# model: used to restore the task-specific model# errors: dictionary to restore defined loss functions of different levels# scores: dictionary to restore defined accuracies functions# optimizer: dictonary to restore optimized chosen for inner and outer loop optimization
# 例子ex = boml.Experiment(datasets = dataset)ex.errors['training'] = boml.utils.cross_entropy(pred=ex.model.out,label=ex.y,method='MetaRper')
ex.scores['accuracy'] = tf.contrib.metrics.accuracy(tf.argmax(tf.nn.softmax(ex.model.out), 1),tf.argmax(ex.y, 1))
ex.optimizer['apply_updates'], _ = boml.BOMLOptSGD(learning_rate=lr0).minimize(ex.errors['training'],var_list=ex.model.var_list)BOMLOptimizer: BOMLOptimizer is the main class in boml, which takes responsibility for the whole process of model construnction and back propagation.
xxxxxxxxxxboml.BOMLOptimizer( Method=None, inner_method=None, outer_method=None, truncate_iter=-1, experiments=[] )Method: define basic method for following training process, it should be included in [MetaInit, MetaRepr], MetaInit type includes methods like MAML, FOMAML, MT-net, WarpGrad; MetaRepr type includes methods like BA, RHG, TG, HOAG, DARTS;
inner_method: method chosen for solving LLproblem, including [Trad , Simple, Aggr], MetaRepr type choose either Trad for traditional optimization strategies or Aggr for Gradient Aggragation optimization. MetaInit type should choose Simple, and set specific parameters for detailed method choices like FOMAML or MT-net.
outer_method: method chosen for solving ULproblem, including [Reverse ,Simple, DARTS, Implcit], MetaInit type should choose Simple, and set specific parameters for detailed method choices like FOMAML.
truncate_iter: specific parameter for Truncated Gradient method, defining number of iterations to truncate in the Back propagation process
experiments: list of Experiment objects that has already been initialized.
xxxxxxxxxx# 例子ex = boml.Experiment(boml.meta_omniglot(5,1,15))boml_ho = boml.BOMLOptimizer(Method='MetaRper',inner_method='Simple',outer_method='Simple',experiments=ex)
5 核心内置函数
参考页面:https://boml.readthedocs.io/en/latest/builtin.html
BOMLOptimizer.meta_learner: This method must be called once at first to build meta modules and initialize meta parameters and neural networks.
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.meta_learner( _input, # _input: orginal input for neural network construction; dataset, # dataset: which dataset to use for training and testing. It should be initialized before being passed into the function meta_model='V1',# meta_model: model chosen for neural network construction, V1 for C4L with fully connected layer,`V2` for Residual blocks with fully connected layer. name='Hyper_Net', # name: name for Meta model modules used for BOMLNet initialization use_t=False, # use_t: whether to use T layer for C4L neural networks use_warp=False, # use_warp: whether to use Warp layer for C4L neural networks **model_args # model_args: optional arguments to set specific parameters of neural networks.)BOMLOptimizer.base_learner: This method has to be called for every experiment and takes responsibility for defining task-specific modules and inner optimizer.
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.base_learner( _input, # _input: orginal input for neural network construction of task-specific module; meta_learner, name='Task_Net', # meta_learner: returned value of meta_learner function, which is a instance of BOMLNet or its child classes weights_initializer=tf.zeros_initializer # weights_initializer: initializer function for task_specific network, called by ‘MetaRepr’ method)BOMLOptimizer.ll_problem: After construction of neural networks, solutions to lower level problems should be regulated in ll_problem.
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.ll_problem( inner_objective, # loss function for the inner optimization problem learning_rate, # step size for inner loop optimization T, # numbers of steps for inner gradient descent optimization inner_objective_optimizer='SGD', # Optimizer type for the outer parameters, should be in list [SGD,`Momentum`,`Adam`] outer_objective=None, # loss function for the outer optimization problem, which need to be claimed in BDA agorithm learn_lr=False, alpha_init=0.0, # initial value of ratio of inner objective to outer objective in BDA algorithm s=1.0, t=1.0, # coefficients of aggregation of inner and outer objectives in BDA algorithm, default to be 1.0 learn_alpha=False, # specify parameter for BDA algorithm to decide whether to initialize alpha as a hyper parameter learn_st=False, # specify parameter for BDA algorithm to decide whether to initialize s and t as hyper parameters learn_alpha_itr=False, # parameter for BDA algorithm to specify whether to initialize alpha as a vector, of which every dimension’s value is step-wise scale factor fot the optimization process var_list=None, # optional list of variables (of the inner optimization problem) init_dynamics_dict=None, first_order=False, # specific parameter to define whether to use implement first order MAML, default to be FALSE loss_func=utils.cross_entropy, # specifying which type of loss function is used for the maml-based method, which should be consistent with the form to compute the inner objective momentum=0.5, # specific parameter for Optimizer.BOMLOptMomentum to set initial value of momentum beta1=0.0, beta2=0.999, regularization=None, # whether to add regularization terms in the inner objective experiment=None, # nstance of Experiment to use in the Lower Level Problem, especifially needed in the MetaRper type of method. scalor=0.0, **inner_kargs # optional arguments to pass to boml.boml_optimizer.BOMLOptimizer.compute_gradients)BOMLOptimizer.ul_problem: This method define upper level problems and choose optimizer to optimize meta parameters, which should be called afer ll_problem.
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.ul_Problem( outer_objective, # scalar tensor for the outer objective meta_learning_rate, # step size for outer loop optimization inner_grad, # Returned value of boml.BOMLOptimizer.LLProblem() meta_param=None, # optional list of outer parameters and model parameters outer_objective_optimizer='Adam', # Optimizer type for the outer parameters, should be in list [SGD,`Momentum`,`Adam`] epsilon=1.0, # Float, cofffecients to be used in DARTS algorithm momentum=0.5, # specific parameters to be used to initialize Momentum algorithm global_step=None)aggregate_all: Finally, aggregate_all has to be called to aggregate gradient of different tasks, and define operations to apply outer gradients and update meta parametes.
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.aggregate_all( aggregation_fn=None, # Optional operation to aggregate multiple outer_gradients (for the same meta parameter),by (default: reduce_mean) gradient_clip=None #optional operation to clip the aggregated outer gradients)run
xxxxxxxxxxboml.boml_optimizer.BOMLOptimizer.run( inner_objective_feed_dicts=None, # inner_objective_feed_dicts: an optional feed dictionary for the inner problem. Can be a function of step, which accounts for, e.g. stochastic gradient descent. outer_objective_feed_dicts=None, # an optional feed dictionary for the outer optimization problem (passed to the evaluation of outer objective). Can be a function of hyper-iterations steps (i.e. global variable), which may account for, e.g. stochastic evaluation of outer objective. session=None, # optional session _skip_hyper_ts=False, _only_hyper_ts=False, callback=None # optional callback function of signature (step (int), feed_dictionary, tf.Session) -> None that are called after every forward iteration.)6 例子分析
example.py的内容
xxxxxxxxxxfrom boml import utilsfrom test_script.script_helper import *
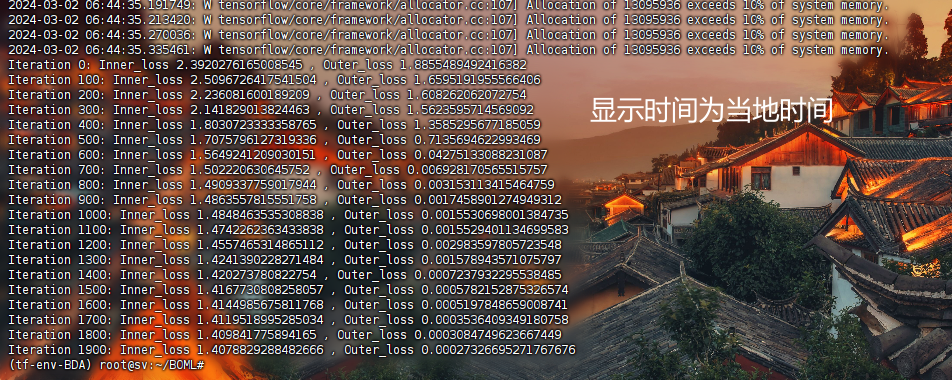
dataset = boml.load_data.meta_omniglot( std_num_classes=args.classes, examples_train=args.examples_train, examples_test=args.examples_test,)ex = boml.BOMLExperiment(dataset)# build network structure and define hyperparametersboml_ho = boml.BOMLOptimizer( method="MetaInit", inner_method="Simple", outer_method="Simple")meta_learner = boml_ho.meta_learner(_input=ex.x, dataset=dataset, meta_model="V1")ex.model = boml_ho.base_learner(_input=ex.x, meta_learner=meta_learner)# define LL objectives and LL calculation processloss_inner = utils.cross_entropy(pred=ex.model.out, label=ex.y)accuracy = utils.classification_acc(pred=ex.model.out, label=ex.y)inner_grad = boml_ho.ll_problem( inner_objective=loss_inner, learning_rate=args.lr, T=args.T, experiment=ex, var_list=ex.model.var_list,)# define UL objectives and UL calculation processloss_outer = utils.cross_entropy(pred=ex.model.re_forward(ex.x_).out, label=ex.y_)boml_ho.ul_problem( outer_objective=loss_outer, meta_learning_rate=args.meta_lr, inner_grad=inner_grad, meta_param=tf.get_collection(boml.extension.GraphKeys.METAPARAMETERS),)# aggregate all the defined operationsboml_ho.aggregate_all()# meta training iterationwith tf.Session() as sess: tf.global_variables_initializer().run(session=sess) for itr in range(args.meta_train_iterations): # generate the feed_dict for calling run() everytime train_batch = BatchQueueMock( dataset.train, 1, args.meta_batch_size, utils.get_rand_state(1) ) tr_fd, v_fd = utils.feed_dict(train_batch.get_single_batch(), ex) # meta training step boml_ho.run(tr_fd, v_fd) if itr % 100 == 0: loss_list=sess.run([loss_inner,loss_outer],utils.merge_dicts(tr_fd,v_fd)) print('Iteration {}: Inner_loss {} , Outer_loss {}'.format(itr, loss_list[0],loss_list[1]))
对第一行 from boml import utils,查看文件 boml中的utils.py
7 要理解代码首先需要解决的问题
导入数据后,数据的结构如何?是以什么形式存储的?
生成的实验(
ex)是什么样的形式?生成的优化模型(
boml_ho)是什么样的形式?上下层损失函数,以及优化方法的具体流程(以一种为例);
完成计算后的数据如何保存,或者是否以某种格式进行了保存?
8 以上述问题为导向理解boml项目
查看python当前环境中的变量,或者用于查看变量的属性或者方法名:
xxxxxxxxxxdir()dir(args)查看变量的值:
xxxxxxxxxxvars(args)在运行了以下代码后,得到的数据以
OmniglotMetaDataset这种类型保存,同时得到实验ex:
xxxxxxxxxximport bomlfrom boml import utilsfrom test_script.script_helper import *
dataset = boml.load_data.meta_omniglot( std_num_classes=args.classes, examples_train=args.examples_train, examples_test=args.examples_test,)# create instance of BOMLExperiment for ong single taskex = boml.BOMLExperiment(dataset)
这种类型OmniglotMetaDataset的所包含的属性/方法如下:
xxxxxxxxxx['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_add_bias', '_data', '_loaded_images', '_rotations', '_shape', '_target', '_tensor_mode', 'args', 'bias', 'convert_to_tensor', 'create_supplier', 'data', 'dim_data', 'dim_target', 'examples_train', 'generate', 'generate_batch', 'generate_datasets', 'info', 'kwargs', 'load_all', 'name', 'num_classes', 'num_examples', 'setting', 'stack', 'target']该类型的定义见(lines 189-266):https://github.com/dut-media-lab/BOML/blob/master/boml/load_data/datasets/load_full_dataset.py#L189
ex的定义见(lines 29-62): https://github.com/dut-media-lab/BOML/blob/master/boml/load_data/experiment.py#L29
其属性或方法如下:
xxxxxxxxxx['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_compute_input_shape', '_compute_output_shape', 'datasets', 'dtype', 'errors', 'model', 'optimizers', 'scores', 'x', 'x_', 'y', 'y_']运行以下代码后得到优化模型
boml_ho,并添加学习方法:
xxxxxxxxxxboml_ho = boml.BOMLOptimizer( method="MetaInit", inner_method="Simple", outer_method="Simple")meta_learner = boml_ho.meta_learner(_input=ex.x, dataset=dataset, meta_model="V1")ex.model = boml_ho.base_learner(_input=ex.x, meta_learner=meta_learner)优化模型boml_ho的定义见(lines 43-629):https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L43
xxxxxxxxxx# 下层目标函数和优化过程loss_inner = utils.cross_entropy(pred=ex.model.out, label=ex.y)accuracy = utils.classification_acc(pred=ex.model.out, label=ex.y)inner_grad = boml_ho.ll_problem( inner_objective=loss_inner, learning_rate=args.lr, T=args.T, experiment=ex, var_list=ex.model.var_list,)# 上层目标函数和优化过程loss_outer = utils.cross_entropy(pred=ex.model.re_forward(ex.x_).out, label=ex.y_) # loss functionboml_ho.ul_problem( outer_objective=loss_outer, meta_learning_rate=args.meta_lr, inner_grad=inner_grad, meta_param=tf.get_collection(boml.extension.GraphKeys.METAPARAMETERS),)
对于下层优化方法,默认使用
SGD: 见https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L242对于上层优化方法,默认使用
Adam: 见https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L400对于上下层目标函数,使用了
cross_entropy,其定义见:https://github.com/dut-media-lab/BOML/blob/master/boml/utils.py#L149
xxxxxxxxxx# Only need to be called once after all the tasks are readyboml_ho.aggregate_all()# 开始训练 with tf.Session() as sess: tf.global_variables_initializer().run(session=sess) for itr in range(args.meta_train_iterations): # Generate the feed_dict for calling run() everytime train_batch = BatchQueueMock( dataset.train, 1, args.meta_batch_size, utils.get_rand_state(1) ) tr_fd, v_fd = utils.feed_dict(train_batch.get_single_batch(), ex) # Meta training step boml_ho.run(tr_fd, v_fd) if itr % 100 == 0: print(sess.run(loss_inner, utils.merge_dicts(tr_fd, v_fd)))聚合所有,返回使用方法的定义在:https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L475
tf.session的说明页面:https://www.tensorflow.org/api_docs/python/tf/compat/v1/Session输出暂时直接显示在运行页面上。
使用boml模拟常见的所有类型的双层优化问题
参考地址:https://github.com/dut-media-lab/BOML
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks(MAML)
Meta-SGD: Learning to Learn Quickly for Few-Shot Learning(Meta-SGD)
Bilevel Programming for Hyperparameter Optimization and Meta-Learning(RHG)
Gradient-Based Meta-Learning with Learned Layerwise Metric and Subspace(MT-net)
可能的选择
对于三个选项可能的选择
method:MetaInit,MetaFeat
MetaInit包括MAML,FOMAML,MT-net,WarpGardMetaFeat包括BDA,RHG,TRHG,Implicit HG,DARTS
inner_method:Trad,Simple,Aggr
MetaFeattype choose eitherTradfor traditional optimization strategies orAggrfor Gradient Aggregation optimizationMetaInittype should chooseSimple, and set specific parameters for detailed method choices likeFMAMLorMT-net.
outer_method:Reverse,Simple,Forward,Implicit
MetaInittype should chooseSimple, and set specific parameters for detailed method choices likeFMAML
组合(2024年3月6日)
见:https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L75
MetaFeat->Simple->Simple: 结果见MFSS
{kind=link}
MetaFeat->Aggr->Darts: 结果见MFAD
{kind=link}
MetaFeat->Aggr->Reverse: 结果见MFAR
{kind=link}
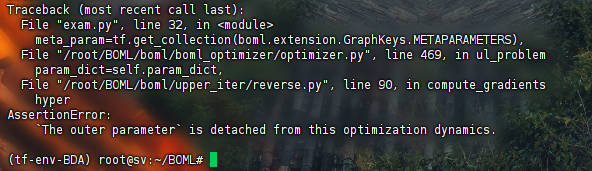
MetaFeat->Trad->Reverse: 结果见MFTR
{kind=link}
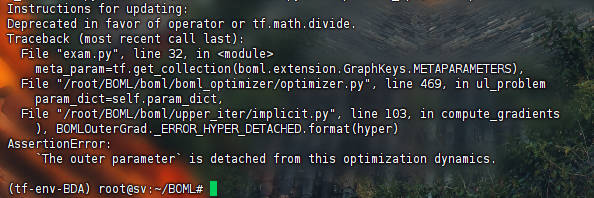
MetaFeat->Trad->Implicit: 结果见MFTI
{kind=link}
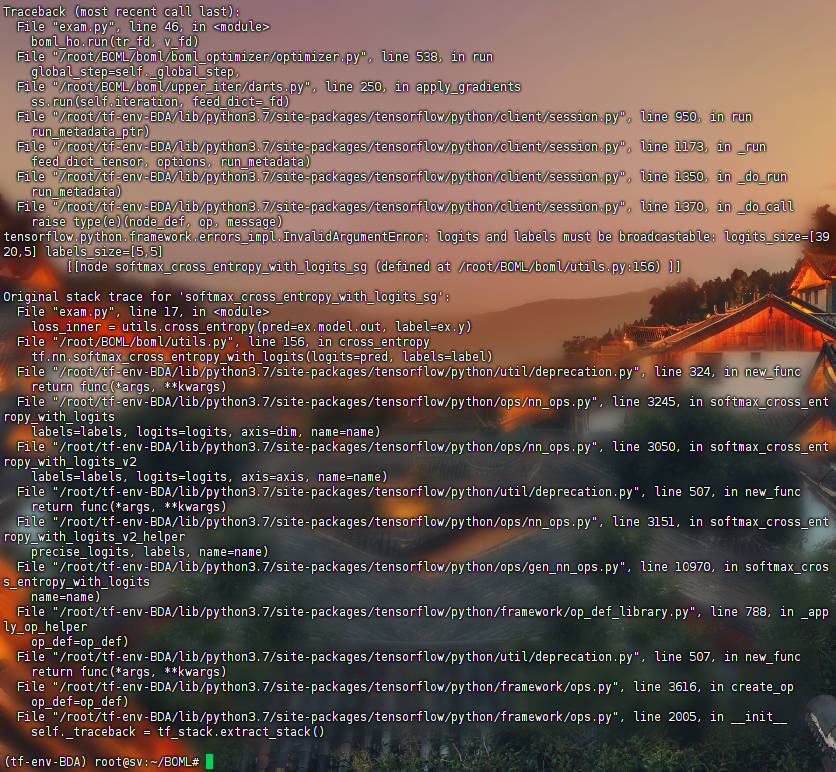
MetaFeat->Trad->Darts: 结果见MFTD
{kind=link}
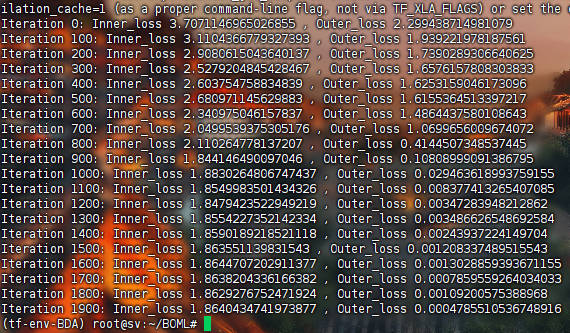
MetaInit->Simple->Simple: 默认配置,结果见MISS
{kind=link}
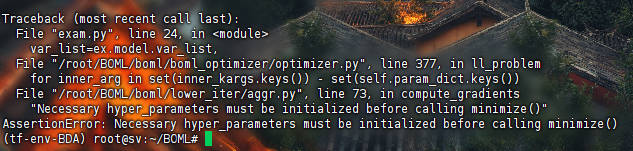
MetaInit->Aggr->Darts: 结果见MIAD, 有bug,参数配置问题
{kind=link}
MetaInit->Aggr->Reverse: 结果见MIAR, 有bug,参数配置问题
{kind=link}
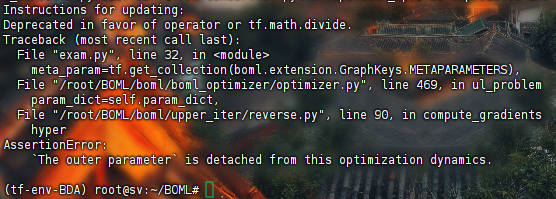
MetaInit->Trad->Reverse : 结果见MITR, 有bug,
{kind=link}
MetaInit->Trad->Implicit: 结果见MITI, 有bug,
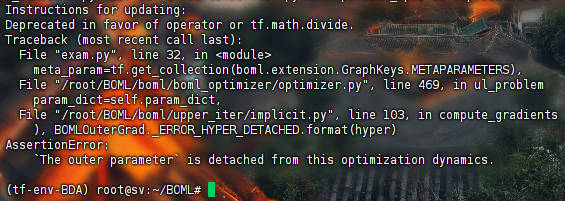{kind=link}
MetaInit->Trad->Darts: 结果见MITD, 有bug,
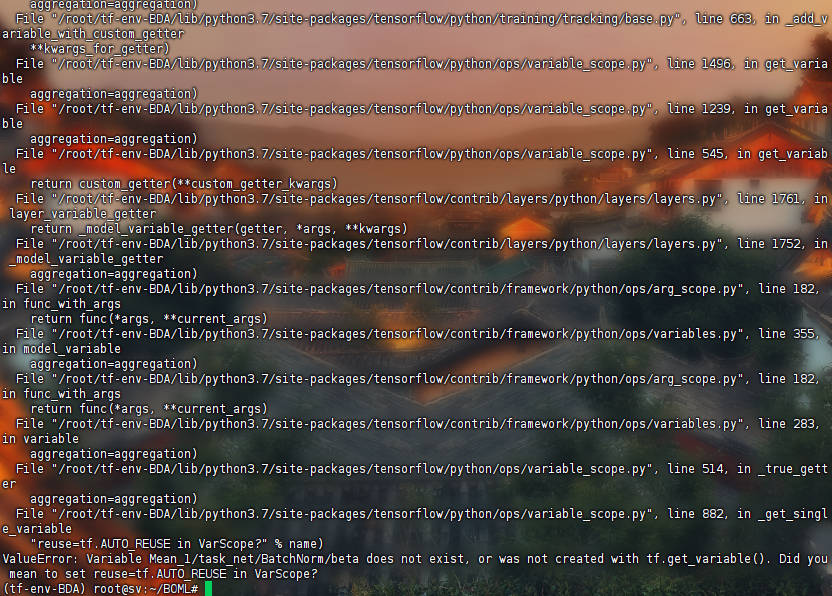{kind=link}
问题总结分类:
hpyer_parameter需要被初始化,AssertionError(MIAD,MIAR)outer parameter需要在优化中分离,AssertionError(MITR, MITI, MFTR, MFTR, MFTI)值不存在,
ValueError(MITD)first_order,KeyError(MFSS)BDA问题,AssertionError(MFAD, MFAR)其他(MFTD)
具体Debug和分析(3月13日)
第一个:MFSS
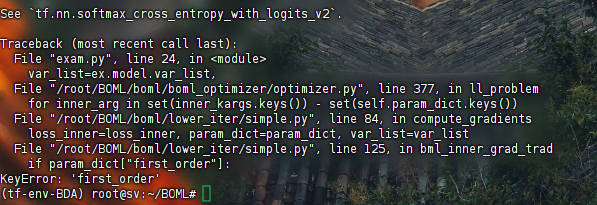
MFSS: 关注字典param_dict的字段first_order没有定义的问题;
该字段的定义在:https://github.com/dut-media-lab/BOML/blob/master/boml/lower_iter/simple.py#L63
其类型为OrderedDict,在此处从collections中引入了OrderedDict;
其中collections是python的一个内置包,用于在python3.7之前保留字典的插入顺序。
在此处给出了:param_dict是不同算法的通用参数的字典;
进一步发现first_order的定义在:https://github.com/dut-media-lab/BOML/blob/master/boml/boml_optimizer/optimizer.py#L271
其是一个特殊的参数用于定义是否执行一阶MAML(FMAML),默认是FALSE;
第二个:MISS
这个可以运行,尝试从具体的运行逻辑上认识整个程序;
发现有其他三个可以运行的版本
下面目标更新为分析以下代码:https://github.com/dut-media-lab/BOML/tree/master/exp_scripts
run_maml_simple_version.sh: 执行文件test_meta_init.py --name_of_args_json_file maml_simple_version.json
maml_simple_version.json文件:
xxxxxxxxxx{ "mode":"train", "dataset":"omniglot", "classes":5, "T":5, "meta_lr":0.001, "lr":0.1, "examples_train":1, "examples_test":15, "meta_batch_size":4, "meta_train_iterations":5000, "method": "MetaInit", "inner_method":"Simple", "outer_method":"Simple", "learn_lr":"false", "logdir":"../tmp/", "print_interval":100, "save_interval":100}run_rhg_simple_version.sh: 执行文件test_meta_feat.py --name_of_args_json_file rhg_simple_version.json
rhg_simple_version.json文件:
xxxxxxxxxx{ "mode":"train", "dataset":"omniglot", "classes":5, "T":5, "meta_lr":0.001, "lr":0.1, "examples_train":1, "examples_test":15, "meta_batch_size":8, "meta_train_iterations":5000, "method":"MetaFeat", "inner_method": "Trad", "outer_method":"Reverse", "learn_lr":"false", "logdir":".../tmp/", "print_interval":100, "save_interval":100}
# 以下代码放在 # https://file.cz123.top/3PhD/4BDA/Codes/test.json{ "mode": "train", "name_of_args_json_file": "../test/test.json", "dataset": "omniglot", "classes": 9, "examples_train": 1, "examples_test": 15, "seed": 0, "meta_batch_size": 8, "meta_train_iterations": 2000, "T": 9, "xavier": false, "batch_norm": false, "meta_lr": 0.001, "meta_lr_decay_rate": 0.00001, "clip_value": 0, "lr": 0.1, "truncate_iter": -1, "alpha_decay": 0.00001, "learn_lr": false, "learn_st": false, "learn_alpha": false, "learn_alpha_itr": false, "regularization": null, "alpha": 0, "bda_s": 1, "bda_t": 1, "method": "MetaFeat", "inner_method": "Trad", "outer_method": "Reverse", "use_t": false, "use_warp": false, "first_order": false, "reptile": false, "inner_opt": "SGD", "outer_opt": "Adam", "log": false, "logdir": ".../tmp/", "resume": true, "print_interval": 100, "save_interval": 100, "test_episodes": 600, "expdir": null, "iterations_to_test": [ 40000 ], "Notes": "Notes"}run_trhg_simple_version.sh: 执行文件test_meta_feat.py --name_of_args_json_file trhg_simple_version.json
trhg_simple_version.json文件:
xxxxxxxxxx{ "mode":"train", "dataset":"omniglot", "classes":5, "examples_train":1, "examples_test":15, "T":5, "meta_lr":0.001, "lr":0.1, "meta_batch_size":8, "meta_train_iterations":5000, "method":"MetaFeat", "inner_method": "Trad", "outer_method":"Reverse", "learn_lr":"false", "logdir":".../tmp/", "truncate_iter": 1, "print_interval":100, "save_interval":100}例子脚本的使用与修改
test_meta_init.py参看:https://github.com/dut-media-lab/BOML/blob/master/test_script/test_meta_init.py
以下是一段可以用于修改的脚本
xxxxxxxxxxcd ~/BOMLmkdir test && cd ./test
# 创建配置文件cat <<EOF > test.json{ "mode":"train", "dataset":"omniglot", "classes":5, "T":2, "meta_lr":0.001, "lr":0.1, "examples_train":1, "examples_test":15, "meta_batch_size":20, "meta_train_iterations":2000, "method":"MetaFeat", "inner_method": "Trad", "outer_method":"Reverse", "learn_lr":"false", "logdir":".../tmp/", "print_interval":50, "save_interval":200}EOF
# 创建运行文件 (针对于meta_feat这种情况)cat <<EOF > run.shcd ../test_scriptpython test_meta_feat.py --name_of_args_json_file ../test/test.jsonEOF
bash run.sh
其他
一段用于在python命令行环境中的代码(容易复制)
xxxxxxxxxxfrom boml import utilsfrom test_script.script_helper import *
dataset = boml.load_data.meta_omniglot(std_num_classes=args.classes,examples_train=args.examples_train,examples_test=args.examples_test,)
ex = boml.BOMLExperiment(dataset)boml_ho = boml.BOMLOptimizer(method="MetaInit", inner_method="Simple", outer_method="Simple")meta_learner = boml_ho.meta_learner(_input=ex.x, dataset=dataset, meta_model="V1")ex.model = boml_ho.base_learner(_input=ex.x, meta_learner=meta_learner)
loss_inner = utils.cross_entropy(pred=ex.model.out, label=ex.y)accuracy = utils.classification_acc(pred=ex.model.out, label=ex.y)
inner_grad = boml_ho.ll_problem(inner_objective=loss_inner,learning_rate=args.lr,T=args.T,experiment=ex,var_list=ex.model.var_list,)
loss_outer = utils.cross_entropy(pred=ex.model.re_forward(ex.x_).out, label=ex.y_)boml_ho.ul_problem(outer_objective=loss_outer,meta_learning_rate=args.meta_lr,inner_grad=inner_grad,meta_param=tf.get_collection(boml.extension.GraphKeys.METAPARAMETERS),)
boml_ho.aggregate_all()
with tf.Session() as sess: tf.global_variables_initializer().run(session=sess) for itr in range(args.meta_train_iterations): train_batch = BatchQueueMock(dataset.train, 1, args.meta_batch_size, utils.get_rand_state(1)) tr_fd, v_fd = utils.feed_dict(train_batch.get_single_batch(), ex) boml_ho.run(tr_fd, v_fd) if itr % 100 == 0: loss_list=sess.run([loss_inner,loss_outer],utils.merge_dicts(tr_fd,v_fd)) print('Iteration {}: Inner_loss {} , Outer_loss {}'.format(itr, loss_list[0],loss_list[1]))